Sentimentify
Spotify Review Sentiment Analysis
Enter your Spotify review below:
About Sentiment Analysis
This analysis was performed using a DistilBERT model fine-tuned on thousands of Spotify reviews. The model classifies reviews as positive, neutral, or negative based on the text content. While generally accurate, be aware that it may occasionally produce false-positive or false-negative predictions.
Your Review History
Model Training Results
check_circle Accuracy Metrics
grid_view Confusion Matrix
| Predicted Negative |
Predicted Neutral |
Predicted Positive |
|
|---|---|---|---|
| Actual Negative |
8451 | 1001 | 325 |
| Actual Neutral |
837 | 8524 | 417 |
| Actual Positive |
458 | 1020 | 8300 |
timeline Training History
architecture Model Architecture
Base Model: DistilBERT (distilbert-base-uncased)
Parameters: 66M
Layers: 6 transformer blocks
Embedding Size: 768
Training Epochs: 10 (with early stopping)
Batch Size: 32
analytics Final Classification Report
| Precision | Recall | F1-score | Support | |
|---|---|---|---|---|
| negative | 0.867 | 0.864 | 0.866 | 9777 |
| neutral | 0.808 | 0.872 | 0.839 | 9778 |
| positive | 0.918 | 0.849 | 0.882 | 9778 |
| accuracy | 0.862 | 29333 | ||
| macro avg | 0.864 | 0.862 | 0.862 | 29333 |
| weighted avg | 0.864 | 0.862 | 0.862 | 29333 |
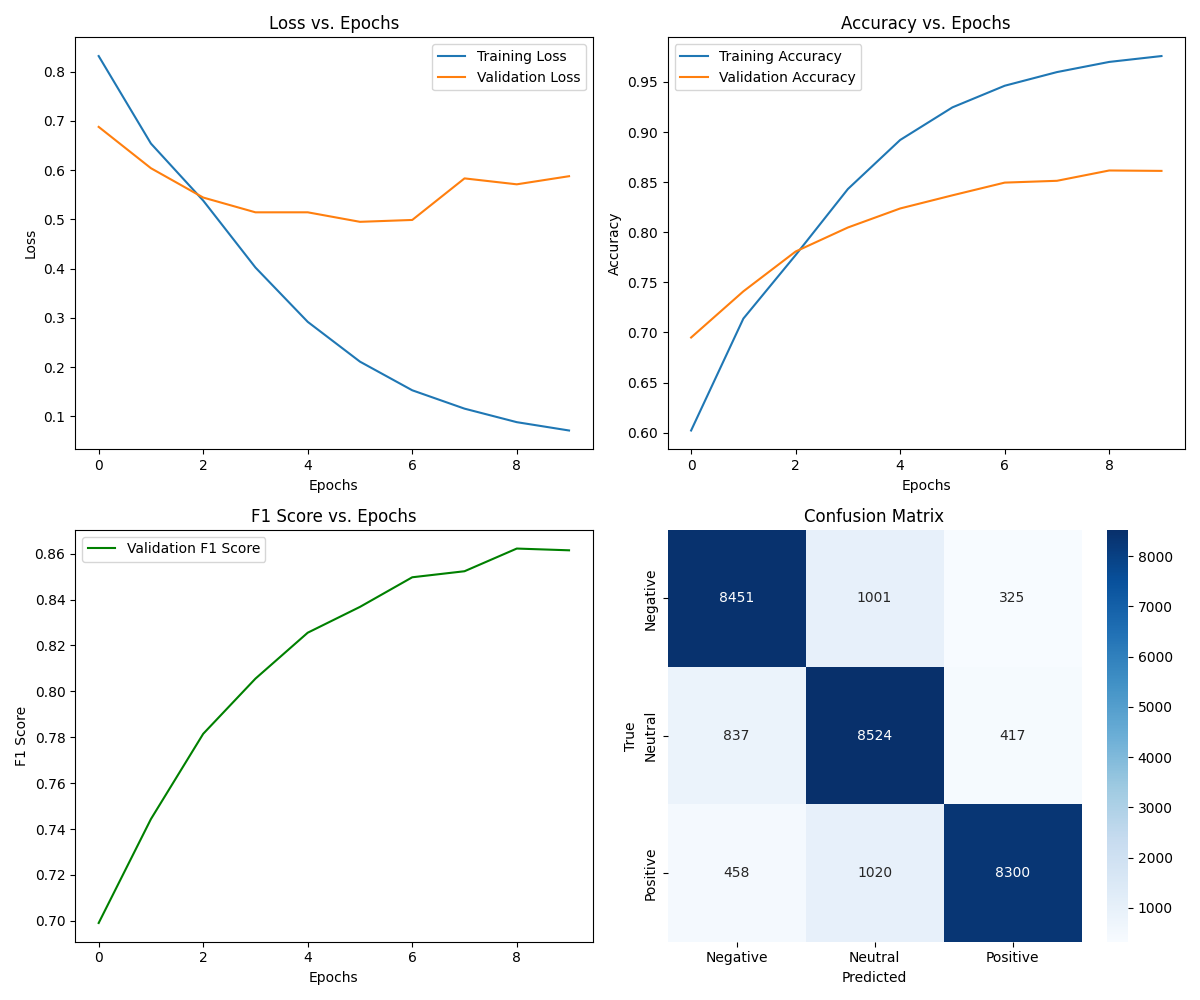
The classification report shows detailed metrics for each sentiment class. The positive sentiment class has the highest precision (0.918) but a lower recall (0.849), indicating that while the model is very confident when predicting positive sentiment, it sometimes misses positive reviews. Neutral sentiment has the highest recall (0.872) but lowest precision (0.808), suggesting the model tends to categorize some negative and positive reviews as neutral.
Model Performance
The DistilBERT model achieved a final accuracy of 86.17% on the validation set, with a balanced F1 score of 0.8622 across all classes. The confusion matrix indicates that the model performs well in distinguishing between positive and negative sentiments, with minor confusion primarily occurring between neutral and other classes.
Training Progress
| Epoch | Training Loss | Training Accuracy | Validation Loss | Validation Accuracy | F1 Score |
|---|---|---|---|---|---|
| 1 | 0.8318 | 60.22% | 0.6880 | 69.50% | 0.6991 |
| 2 | 0.6541 | 71.39% | 0.6040 | 74.10% | 0.7444 |
| 3 | 0.5383 | 77.72% | 0.5445 | 78.08% | 0.7815 |
| 4 | 0.4023 | 84.32% | 0.5144 | 80.48% | 0.8056 |
| 5 | 0.2920 | 89.21% | 0.5145 | 82.37% | 0.8256 |
| 6 | 0.2111 | 92.47% | 0.4951 | 83.69% | 0.8368 |
| 7 | 0.1530 | 94.62% | 0.4989 | 84.96% | 0.8497 |
| 8 | 0.1157 | 95.99% | 0.5834 | 85.14% | 0.8523 |
| 9 | 0.0883 | 97.00% | 0.5713 | 86.17% | 0.8622 |
| 10* | 0.0713 | 97.59% | 0.5878 | 86.12% | 0.8615 |
*Early stopping triggered after epoch 10 due to no improvement in validation metrics
Training Insights
- Consistent Progress: The model showed steady improvement throughout training, with accuracy increasing from 60% to 97% on the training set.
- Early Stopping: Training stopped after epoch 10 as validation metrics began to plateau, preventing overfitting.
- Optimal Performance: The best model was achieved at epoch 9 with 86.17% validation accuracy and 0.8622 F1 score.
- Training-Validation Gap: The final training accuracy (97%) was higher than validation accuracy (86%), indicating some degree of overfitting despite regularization techniques.
Performance Analysis
- Class Imbalance Handling: Despite initially imbalanced data, the model achieved similar performance across all sentiment classes.
- Validation Loss: While training loss continuously decreased, validation loss stabilized around epoch 6, suggesting the model reached optimal generalization capacity.
- Learning Rate Impact: The adaptive learning rate with the AdamW optimizer (2e-5) proved effective for this task, allowing rapid initial learning that gradually stabilized.
- Batch Effects: Gradient accumulation helped stabilize training with the effective batch size of 64 (32×2).
insights Key Observations
- The model demonstrated significant learning in the first 3 epochs, with validation accuracy improving from 69.50% to 78.08%.
- Between epochs 4-8, improvements were more gradual, suggesting deeper feature learning.
- The gap between training and validation metrics widened after epoch 5, indicating the model was beginning to memorize training examples.
- Early stopping at epoch 9 was optimal, as epoch 10 showed signs of overfitting with increased validation loss and slightly decreased F1 score.
About the Model
I chose DistilBERT for this sentiment analysis application as the model can understand complex linguistic patterns in user reviews while maintaining efficiency. As a lightweight transformer model, DistilBERT requires fewer computational resources than its larger counterparts while still capturing the nuances of sentiment in text. It processes reviews quickly, making it ideal for a responsive web application. The model is less likely to overfit on the training data, which helps maintain accuracy across various review styles and vocabularies. Additionally, DistilBERT's balance between performance and efficiency made it the optimal choice for analyzing Spotify reviews in real-time without compromising on understanding the emotional context behind user feedback.
Model Training Process
The training process involved several important steps:
- Enhanced data cleaning with emoji handling and text normalization
- Balanced dataset creation through augmentation techniques
- Training using AdamW optimizer with learning rate of 2e-5
- Implementation of early stopping to prevent overfitting
- Mixed precision training for improved performance
- Gradient accumulation for stability with larger effective batch sizes